


ABSTRACT
The Reliability Value Chain provides a systematic approach to optimizing asset reliability in top-performing enterprises. Global businesses should strive for consistent, standards-based reliability practices throughout their plants. The short-comings of ad-hoc or laissez faire approaches that allow inconsistent practices at different plants are well documented. Understanding the Reliability Value Chain and addressing imbalances and broken links brings enterprises into the top-performing quartile.
A business problem
Global enterprises are challenged to find the resources needed to implement asset management systems consistently across their global fleet of assets. Chances are good that your organization spends too much on maintenance and receives too little in return. This fact simply means that you have opportunities for benefits in both maintenance and operations. Executives are interested in this because they recognize significant opportunities to improve profitability, availability, and safety. In fact, a company with multiple plants can uncover even greater savings and significantly increase shareholder value.
“Every 1% gain in availability is worth $8.4 million of additional margin capture per year in a typical 200,000 bpd refinery.” Doug White, Emerson industry expert – based on current refinery economics
A Solomon Associates global study of reliability practices measured maintenance costs as a function of the replacement value of the assets. If a top-performing site spends 10 million dollars per year on maintenance, a poor performing plant will spend orders of magnitude more — three and one half times more — for the same size plant. In most cases, the value of the operational benefits is three to seven times the value of the maintenance-spend reduction. The value of moving into the top-performing quartile is high. According to the same study, top-quartile plants also experience very little down time as a result of equipment problems. Fourth-quartile (poorest) performers experience disruptive levels of down time that are almost 15-percent greater than top performers.
A big difference
Research also shows that a top-quartile performing organization possesses a ‘Reliability Value Chain’, a set of well-linked elements in four categories: data, information, knowledge, and action — as shown in Figure 1. This sets the path for transforming data into information, into knowledge, and into action. Ultimately, the ability to achieve top performance status is dependent on the robustness of each element and, perhaps more importantly, on the effective connectedness of all of the elements into a continuous improvement cycle.
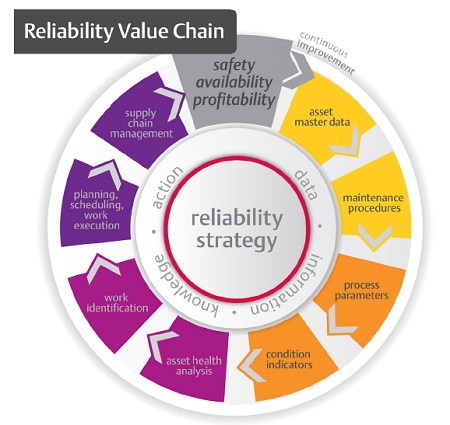
The Reliability Value Chain
Improving each ring in the reliability value chain — and improving the links between them — leads to significant reductions in maintenance spending as well as significant decreases in unscheduled downtime.
Reliability strategy, the analyses used to understand and catalogue failure modes, is pivotal to the value chain. The core of reliability strategy emanates radially and shapes all facets of the chain. For instance, the characteristics and classifications chosen to characterize asset master data are driven by the requirements of the reliability strategy. Further, the mitigation of failure modes drives the selection of maintenance procedures, process parameter data, condition indicators, and spares stocking strategies. Asset health analysis is interpreted from an understanding of the failure effects observed from process data and condition indicators. Most importantly, setting the reliability strategy must strike a balance between the engineering characteristics of the assets and the capabilities of the organization to perform the function required within each ring in the chain.
Let us now examine each area of the chain and determine potential opportunities for growth. DATA elements are necessary as the foundational enablers for reliability. The foundation includes asset master data: a complete and accurate list of equipment that includes equipment physical attributes, importance of the equipment to the enterprise, and more. Important is a logical location hierarchy that facilitates subsequent analysis; the parts and technical information that relate to the asset; and the appropriate failure codes that will enable feedback and refinement of maintenance strategies. Foundational data also includes the maintenance procedures that are performed to monitor and maintain the assets in healthy condition.
This foundational data will be used throughout the chain, establishing what conditions indicate poor health. Understanding conditions helps technicians understand how the equipment behaves or fails, which in turn helps define the early warning signs that identify whether the asset is in distress. Actions can then be taken to prevent failure or mitigate the consequences of failure. These procedures are developed as a result of various analyses such as Reliability-Centered Maintenance (RCM) and Failure Modes and Effects Analysis (FMEA). Proper and consistent use of these analytical tools for a particular class of asset throughout the enterprise will lead to the optimum set of maintenance procedures for that asset class: how best to maintain and monitor that equipment. Allowing a variety of maintenance procedures to be applied to the same equipment at different plants is an outdated and unacceptable practice in today’s modern world of reliability.
INFORMATION is derived from asset condition indicators and process parameters that have been collected and analyzed. Asset condition indicators are routinely used to monitor and analyze asset health and come from predictive technologies and from condition monitoring capabilities like vibration analysis, oil analysis, infrared thermography, ultrasonic leak inspection, and other modes of machinery health monitoring. Process data (temperature, pressure, flow, etc.) — available in almost every plant via the distributed control system — is typically used only for plant operation and control. The new standard of practice for top-quartile performers requires leveraging this data for maintenance purposes.
The process data and the condition indicators are contained often in separate silos or databases with separate methods of access. An accurate understanding of equipment and process health relies on the data being connected together. To obtain useful information, process condition data and equipment health data must be brought together in a robust dashboard or view. The view must cross-reference which specific process parameter sensors provide information about which assets.
KNOWLEDGE comes from the union of asset health analysis and work identification — a culmination of experience. It is the result of interpreting data and information, then drawing conclusions. For example, we might find a high vibration reading on a pump, low discharge pressure, and an erratic discharge flow rate. That combination tells us we have a problem. But what is the problem? Together, vibration analysis, experience, and process knowledge might indicate that cavitation is likely to be the problem. This call would be much more difficult using vibration analysis alone.
We must have accurate data and solid experience to know what is good and what is normal. The foundational data, if rendered properly, will establish what is normal for each asset. The deployed monitoring technologies will alert us when abnormal conditions are reached, so that an expert can review the information and diagnose the problem.
ACTION translates knowledge into a traditional work management process, which is the oldest part of maintenance: planning, scheduling, and work execution plus supply chain management. When abnormal conditions are found and proper diagnosis is established, a work order can be generated to correct the condition. But in lower-quartile performers, inefficiencies and associated costs arise because repairs come mostly from urgent or emergency failures of equipment. That is because in those plants the information and knowledge areas have not been deployed effectively. Facilities do not detect early warning signs of failures. This is a very reactive way of working which can be eliminated with effective deployment of technology available today.
Organisational priorities can also cause reactive maintenance. For example, an analyst might say there is something wrong with the equipment based on the analysis techniques deployed. But the operators rely on their human senses and might not bring the machine to a stop for repairs because they cannot see, smell, hear, or feel anything wrong with the equipment. This is a typical cultural bias that must be altered to allow operators to understand and trust what the technology is telling us about the health of an asset. Operators and managers need to understand that while it may feel counter-intuitive to remove a seemingly healthy machine from service, in the long run that machine will deliver more reliable production if removed from service now for a short, well-managed restoration.
Top-quartile performers rely on solid data, information, and knowledge to obtain a diagnosis. The plant workers trust the diagnosis and they know how to fix the problem and have the tools to put the plans into action. Knowledge guides them to the right actions to avoid unplanned downtime and excess repair costs. In this scenario, all of the links in the Reliability Value Chain are fully connected and effective.
Fundamental Problems: Addressed and Corrected
In most plants the robustness of each element in the chain is lacking or suboptimal. For top-quartile performance, every element in the chain must be optimized. A few common problems are described here.
Asset master data is a fundamental element of success, yet many facilities cannot produce an accurate and complete version of this essential tool. They might have an asset master data list that comes from their asset management system, but not all classes of equipment are represented. Or equipment might have been moved but the asset list was not updated accordingly. In some cases even if all the equipment is listed, and even if locations of equipment are accurately tracked, the level of detail about each piece of equipment is not enough for top-quartile performance. For example, operating in a rudimentary or fourth-quartile mode does not require detailed technical attribute information such as how many gears are in a gear box or what are the gear ratios. But that type of technical attribute information is necessary in a top-quartile practice to perform proper analysis and arrive at effective diagnosis of problems. When this foundational information is faulty, all of the other processes built on this information become suspect and will not enable a company to achieve high-quality results.
Another common problem is an over-reliance on time-based preventive maintenance (PM) procedures that may be recommended by the OEM but that do not address known failure modes, and are therefore adding little if any value (other than driving spare parts sales for the OEMs). Proper analysis and optimization of the PM programme, including deployment of significantly more condition monitoring tools, are necessary to optimize this element. Establishing envelopes of normal operating parameters and setting alarms for abnormal conditions is also fundamental and necessary.
These, and many other issues with various elements in the chain, can and must be addressed and corrected.
Recognising Broken Links and Fixing Them
Whether top performers or lower performers, most companies have all of the elements in the Reliability Value Chain (albeit many of which are sub-optimized). But the elements themselves — even when optimized — do not drive value. The connection points between them do. Top-quartile plants have linked all of the elements effectively. So where are the breaks?
A very prevalent break in the chain is the one between knowing and acting. As alluded to earlier, most plants measure equipment conditions (at least for some equipment), analyze alarms, and recommend work activities, but the operations organization might not trust the information because it emanates from a faulty foundation of master data. In addition, operations might not understand, appreciate, or respect what the science and technology is telling the organization to do. Traditionally, the operations group has been bound to keep the plant running and not take a machine down until there is a definite issue, for example seeing or hearing a problem. These are cultural issues of duty and of understanding, and they hinder the effective linkage between knowing we have a developing problem and doing something about it before significant consequences occur.
Another common broken link is between the process parameter data and condition indicator elements, which are often not combined. This hinders the organization’s ability to make accurate calls about what is wrong and what needs to be done – causing difficulty in keeping later links in the chain properly connected.
There is plenty of work to do in terms of properly linking the elements in the chain and changing the culture of an organization. Although this is difficult to do, our own company has partnered with clients to accomplish it. From the bottom up, we must help operators understand and value technology, analysis, and actionable intelligence. From the top down, executives must understand the business case — financial and otherwise — associated with insisting on non-negotiable reliability standards and best practices. When the business case is established, understood, and believed by the executive management team, the rewards systems start to change as well, and this enables culture change within the organization from top to bottom.
Our own organisation has taken appropriate pages from the management consulting playbook and has incorporated management consulting practices that address the cultural discrepancies. Once we fix the foundational problems, we must ensure that people understand what the information indicates. In the long run, if we trust the knowledge, we have better results — even though it may seem that taking a machine out of service is intuitively not a good idea. We must appreciate that in the long run the organization will attain better operational performance and lower maintenance expense by taking machines out of service well before they fail catastrophically.
The top-down influence combined with the bottom-up influence is necessary and eventually is very effective in terms of organizational cultural transformation. Individual habits that need to change start to change.
Areas Needing Standardisation
Across an enterprise, the master data sets the stage for success, but standardization does not end with master data. It continues into every element of the Reliability Value Chain. But staying with master data for the moment, standardization does not only benefit asset data. It also applies to spare parts. As we work with clients, we find a great deal of duplication of spare parts. For example, unclear taxonomy (how you name things in the store room item catalogue) can lead to duplication of parts and bloated inventories: 6 “bearings for the big green gear box” and 6 “bearings for the crusher” could mean 12 of the same type of bearing. But if you are looking for a specific bearing by its number, and the bearing number was not entered into these 12 bearing records in the catalogue, you might wrongly conclude that you have none of this bearing in stock and buy more.
Beyond master data, the way an enterprise analyzes pieces of equipment and identifies the ways they fail is also important and benefits from standardization. If one facility uses one failure code and another facility uses another code, the two sites will never recognize they could be dealing with similar issues. That means the enterprise needs consistency in the method by which it determines how and why equipment fails. Standardized codes help ensure consistency so that patterns can be seen more easily.
Consistent criticality rating is key in helping to determine what failures are important. Facilities across an enterprise need to base criticality on a core set of priorities rather than opinions of the person on duty that shift, or recent history fresh in the minds of the plant workers. This enables enterprises to deploy resources where there will be the most benefit.
Conclusions
Experience top performance. While implementing standard maintenance practices is a large task that requires solidarity of purpose, standards, tools and experienced partners, the return on investment is large and long-lasting. Further than that, without non-negotiable enterprise-wide standard practices an enterprise can bleed costs and chase solutions that have little effect. Reliability, much like financial reporting and safety, should rise to a strategic level of importance and priority in any industrial company. Executives should insist on consistent standards of practice to drive meaningful business results.
The authors’ own work is driven by the business case and is based on experience, intellectual property, standards, software, and tools. Our experience and our advanced starting point assists enterprises to roll out best practices consistently and see the results. Our goal is to move our clients to top-quartile performance so they can stop wasting time and money on ineffective reliability programmes.
About the authors
Bob DiStefano is Vice President and General Manager, and Bruce Hawkins Director of Technical Excellence, Reliability Consulting, Emerson Process Management, 27 Glen Rd, Sandy Hook, CT 06482, USA.
Tel. (203) 264.0500
© Emerson Process Management 2015. All rights reserved.
Emerson is a trademark of Emerson Electric Co. All other marks are property of their respective owners.
The contents of this publication are presented for informational purposes only, and while every effort has been made to ensure their accuracy, they are not to be construed as warrantees or guarantees, express or implied, regarding the products or services described herein or their use or applicability. All sales are governed by our terms and conditions, which are available on request. We reserve the right to modify or improve the design or specification of such products at any time without notice.